 Everyone has been lately talking about Generative Adversarial Networks, or more famously known as GAN.
My colleagues, interview candidates, my manager, conferences literally EVERYONE.
It seems like the GANs becomes required knowledge for data scientists in bay area.
It also seems that GANs are cool: GANs can generate new celebility face images, generate creative arts or generate the next frame of the video images. AI can think by itself with the power of GAN.
Everyone has been lately talking about Generative Adversarial Networks, or more famously known as GAN.
My colleagues, interview candidates, my manager, conferences literally EVERYONE.
It seems like the GANs becomes required knowledge for data scientists in bay area.
It also seems that GANs are cool: GANs can generate new celebility face images, generate creative arts or generate the next frame of the video images. AI can think by itself with the power of GAN.
Welcome to CelebA
In this notebook, I will explore the CelebA dataset.
Evaluate uncertainty using ensemble models with likelihood loss and adverserial training
Evaluating the quality of predictive uncertainties is challenging as "ground truth" uncertainty is usually not available. Yet, model's confidence about its estimation is often of interest for researchers. If the model can tell "what it knows" or what is "out of distribution", such infomation gives insights about when the researchers should take the point estimates as their face values.
Generate adversarial examples using TensorFlow
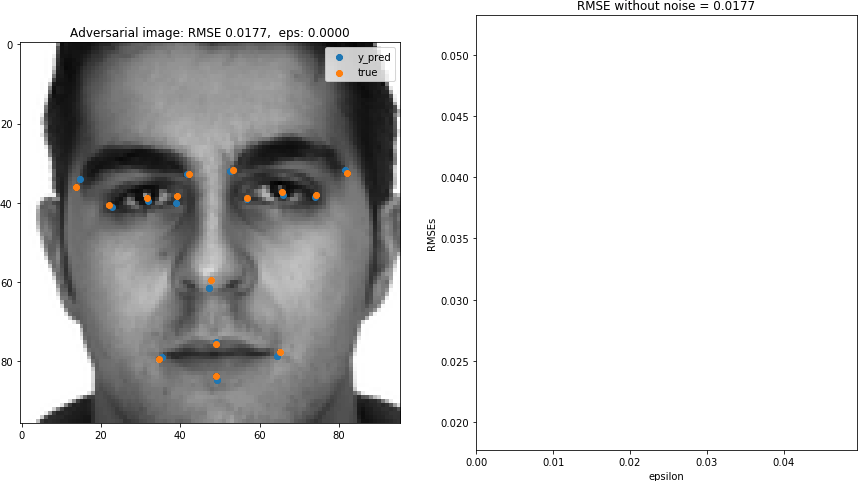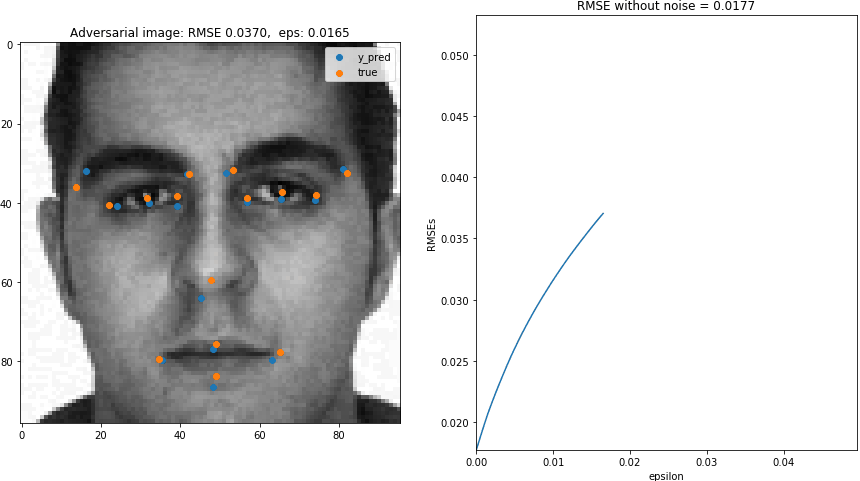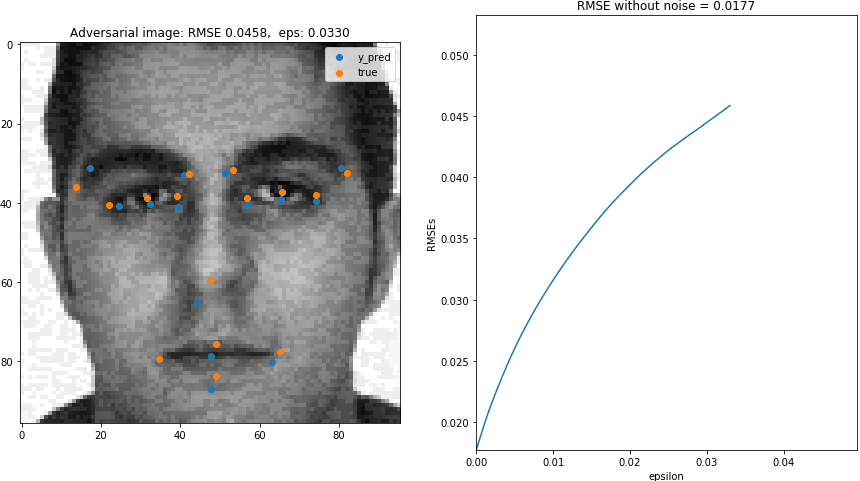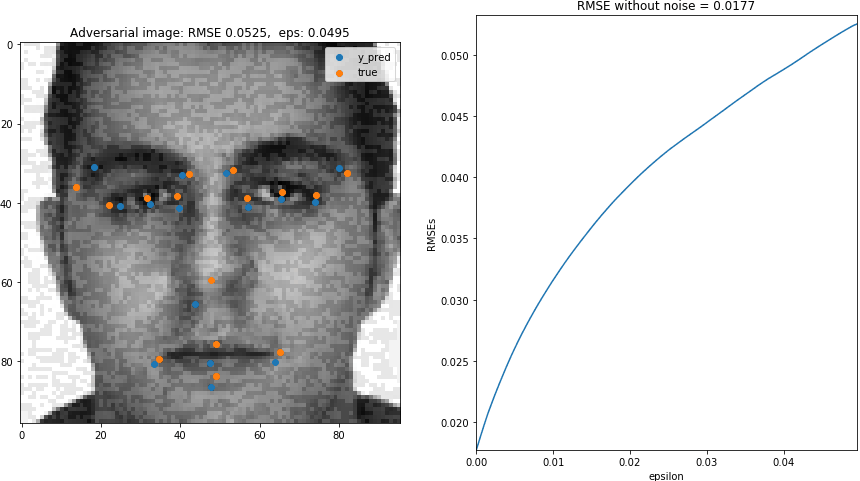
In this blog post, we will generate adversarial images for a pre-trained Keras facial keypoint detection model.
What is adversarial images?¶
According to OpenAI, adversarial examples are:
inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they’re like optical illusions for machines.
Achieving top 5 in Kaggle's facial keypoints detection using FCN
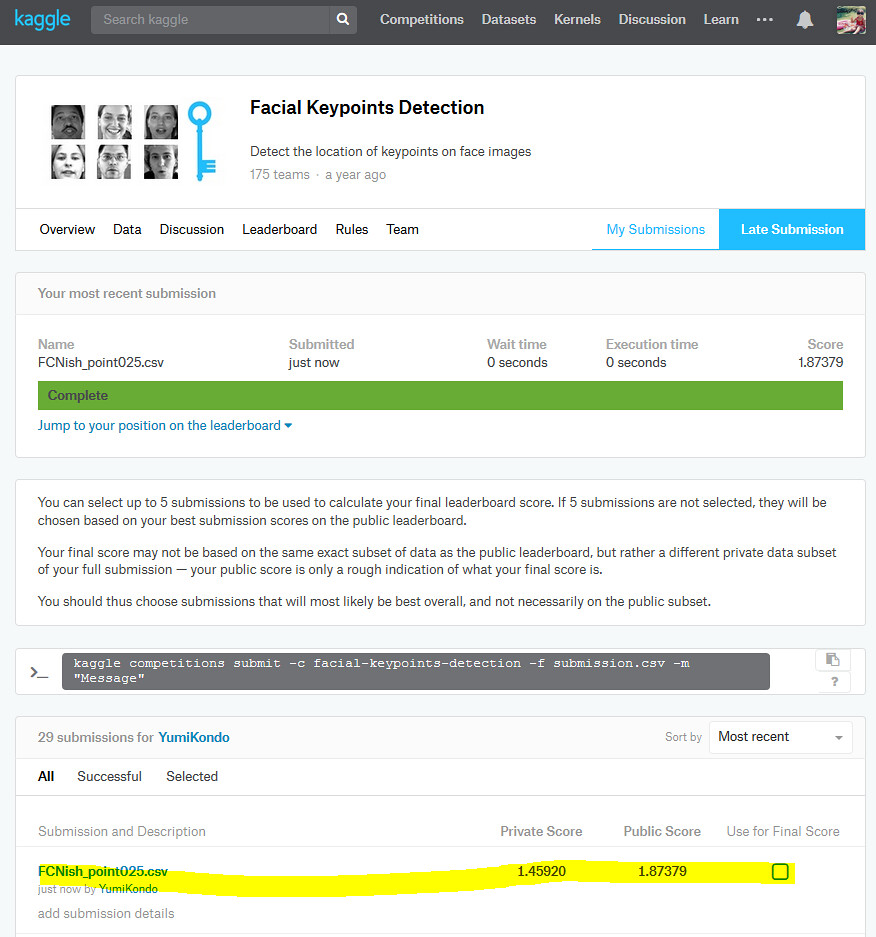
My Kaggle's final score using the model explained in this ipython notebook.
Learn about Fully Convolutional Networks for semantic segmentation
In this blog post, I will learn a semantic segmentation problem and review fully convolutional networks. In an image for the semantic segmentation, each pixcel is usually labeled with the class of its enclosing object or region. For example, a pixcel might belongs to a road, car, building or a person. The semantic segmentation problem requires to make a classification at every pixel.
Driver's facial keypoint detection with data augmentation
 I will revisit
Driver's facial keypoint detection.
In this blog, I will improve the landmark detection model performance with data augmentation.
ImageDataGenerator for the purpose of landmark detection is implemented at my github account and discussed in my previous blog - Data augmentation for facial keypoint detection-.
I will revisit
Driver's facial keypoint detection.
In this blog, I will improve the landmark detection model performance with data augmentation.
ImageDataGenerator for the purpose of landmark detection is implemented at my github account and discussed in my previous blog - Data augmentation for facial keypoint detection-.
Data augmentation for facial keypoint detection

The python class ImageDataGenerator_landmarks is available at my github account. This blog explains about his class.
Why data augmentation?¶
Deep learning model is data greedy and the performance of the model may be surprisingly bad when testing images vary from training images a lot. Data augmentation is an essential technique to utilize limited amount of training images. In my previous blog post, I have seen poor performance of a deep learning model when testing images contain the translation of the training images. However, the model performance improves when training data also contains translated images. See Assess the robustness of CapsNet
Object detection using Haar feature-based cascade classifiers on my face
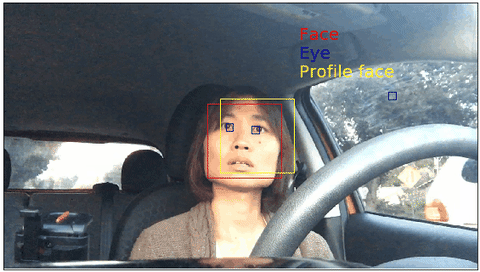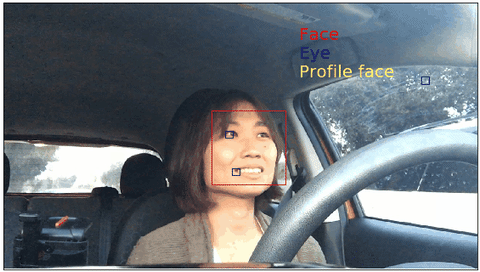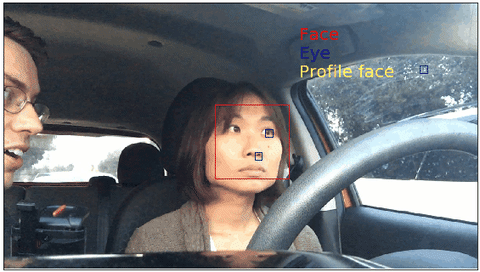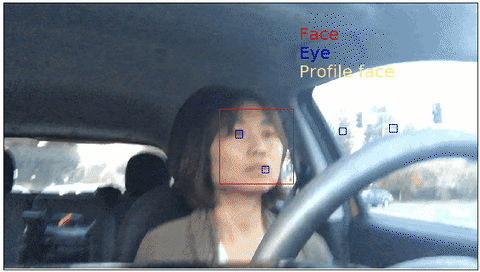
The above gif shows the object detection results from the Haar cascades implemented in OpenCV.
In ths previous blog post Driver's facial keypoint detection, I used public dataset CVC11 to train a facial keypoint detection model. The crucial step in the modeling procedure was to trim image using the face's bounding box. In practice, you might not have access to nice bounding box. In such cases, pre-trained facial detection classifier such as Haar cascade can be useful.
Driver's facial keypoint detection

What you see above is the gif of a driver subject from test data with the estimated facial keypoints.
Evaluation of driving performance is very important to reduce road accident rate. There are a lot of public data related to the driver's faces, including some from the Kaggle competition by State Farm Distracted Driver Detection