Evaluating the quality of predictive uncertainties is challenging as "ground truth" uncertainty is usually not available. Yet, model's confidence about its estimation is often of interest for researchers. If the model can tell "what it knows" or what is "out of distribution", such infomation gives insights about when the researchers should take the point estimates as their face values.
TensorFlow newbie creates a neural net with a negative log likelihood as a loss
In this blog, I will create a deep learning model that uses the negative log-likelihood of Gaussian distribution as a loss. For this purpose, I will use Tensorflow.
Why not Keras?¶
Keras has been my first-choice deep learning framework in the last 1 year. However, if you want to create personal loss functions or layers, Keras requires to use backend functions written in either TensorFlow or Theano. As the negative log-likelihood of Gaussian distribution is not one of the available loss in Keras, I need to implement it in Tensorflow which is often my backend. So this motivated me to learn Tensorflow and write everything in Tensorflow rather than mixing up two frameworks.
Learn about Fully Convolutional Networks for semantic segmentation
In this blog post, I will learn a semantic segmentation problem and review fully convolutional networks. In an image for the semantic segmentation, each pixcel is usually labeled with the class of its enclosing object or region. For example, a pixcel might belongs to a road, car, building or a person. The semantic segmentation problem requires to make a classification at every pixel.
Review on Gaussian process

In this blog post, I would like to review the traditional Gaussian process modeling. This blog was motivated by the blog post Fitting Gaussian Process Models in Python by Christ at Domino which explains the basic of Gaussian process modeling.
When I was reading his blog post, I felt that some mathemtatical details are missing. Therefore, I am writing this blog to digest his blog post.
Measure the uncertainty in deep learning models using dropout
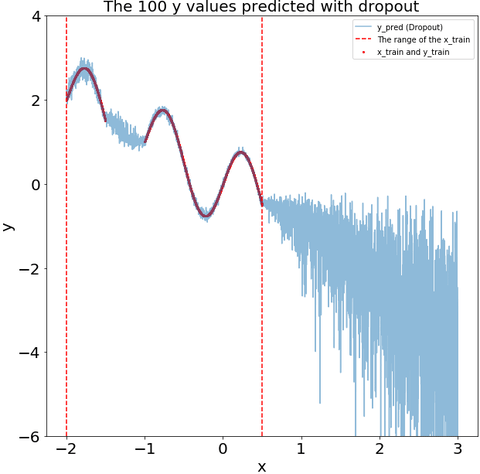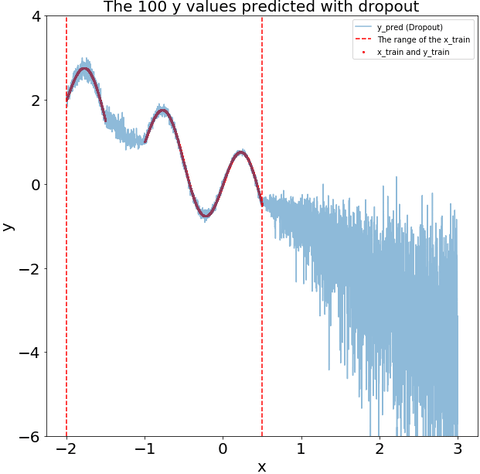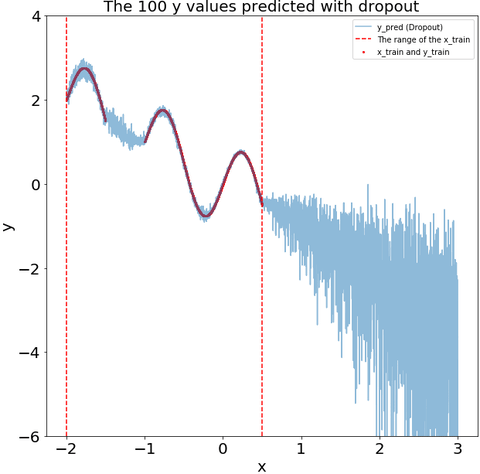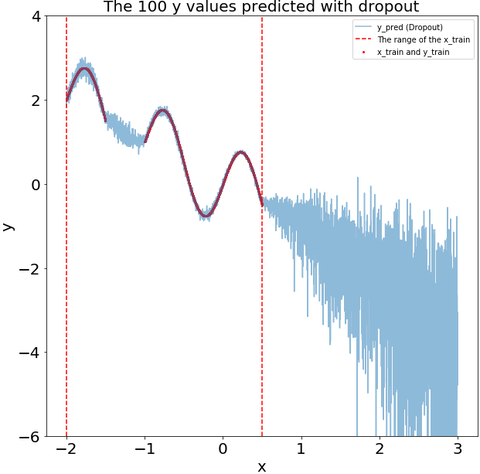
Seminal blog post of Yarin Gal from Cambridge machine learning group What my deep model doesn't know... motivated me to learn how Dropout can be used to describe the uncertainty in my deep learning model.
This blog post is dedicated to learn how to use Dropout to measure the uncertainty using Keras framework.
Stateful LSTM model training in Keras
In the previous post, titled Extract weights from Keras's LSTM and calcualte hidden and cell states, I discussed LSTM model. In this blog post, I would like to discuss the stateful flag in Keras's recurrent model.
If you google "stateful LSTM" or "stateful RNN", google shows many blog posts discussing and puzzling about this notorious parameter, e.g.:
Extract weights from Keras's LSTM and calcualte hidden and cell states
In this blog post, I will review the famous long short-term memory (LSTM) model and try to understand how it is implemented in Keras. If you know nothing about recurrent deep learning model, please read my previous post about recurrent neural network. If you know reccurent neural network (RNN) but not LSTM, you should first read Colah's great blog post
Understand Keras's RNN behind the scenes with a sin wave example - Stateful and Stateless prediction -
Recurrent Neural Network (RNN) has been successful in modeling time series data.
People say that RNN is great for modeling sequential data because it is designed to potentially remember the entire history of the time series to predict values. "In theory" this may be true.
But when it comes to implementation of the RNN model in Keras, practitioners need to specify a "length of time series" in batch_shape: