Introduction¶
How many sample do you need to predict the proportion of fake account in a social network?
Obviously, if human manually check every account one by one for ALL the accounts in the social network, we can get the actual proportion of the fake accounts. But this would be too expensive and time consuming, especially when social accounts nowadays contain billions of active accounts! Facebook has 2 billion users, LinkedIn has .5 billion users.
Gentle Hands-on Introduction to Propensity Score Matching
Introduction¶
Data Scientists need to help making business decisions by providing insights from data. To answer to the questions like "does a new feature improve user engagement?", data scientists may conduct A/B testing to see if there is any "causal" effect of new feature on user's engagement, evaluated with certain metric. Before diving into causal inference in observational study, let's talk about more common approach: A/B testing and its limitation.
Inverse transform sampling and other sampling techniques
Random number generation is important techniques in various statistical modeling, for example, to create Markov Chain Monte Carlo algorithm, or simple Monte Carlo simulation. Here, I make notes on some standard sampling techiniques, and demonstrate its useage in R.
Inverse Transform Sampling¶
Inverse Transform Sampling is a powerful sampling technique because you can generate samples from any distribution with this technique, as long as its cumulative distribution function exists.
Support Vector Machine Review of Prof Patrick Winston's lecture
This blog documents my notes on 16. Learning: Support Vector Machines.
I try to fill the gap in the explanations in Prof Patrick Winston's lecture.
Support Vector Machine problem statement¶
Given two class observations (linearly separable for the sake of problem understanding), find the best line that maximizes the margin (or the distances of the two streets) between + and - observations!

Performing PCA on heatmap
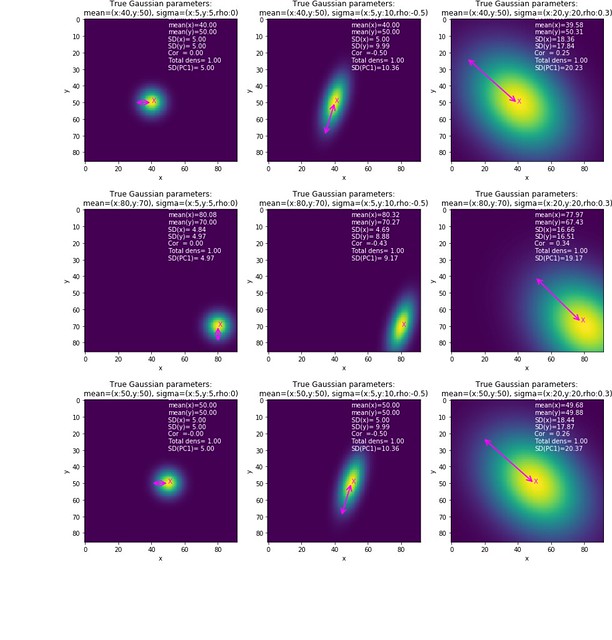
In my previous blog, I reviewed PCA.
The Principal Component Analysis (PCA) techinique is often applied on sample dataframe of shape (Nsample, Nfeat).
In this blog, I will discuss how to obtain the PCA when the provided data is a two-dimensional heatmap.
The two-dimensional heatmap can be thought as a bivariate density on discretized constraint space.
It is discrete because the densiy values are evaluated only at pixcel grids,
and constraint because the grids are bounded.
Review on PCA
Principal Component Analysis (PCA) is a traditional unsupervised dimensionality-reduction techinique that is often used to transform a high-dimensional dataset into a smaller dimensional subspace. PCA seeks a linear combination of variables such that the maximum variance is extracted from the variables. In this blog, I will review this one of the most used applied mathematics teqhiniques.
Review on Gaussian process

In this blog post, I would like to review the traditional Gaussian process modeling. This blog was motivated by the blog post Fitting Gaussian Process Models in Python by Christ at Domino which explains the basic of Gaussian process modeling.
When I was reading his blog post, I felt that some mathemtatical details are missing. Therefore, I am writing this blog to digest his blog post.